Welcome to DataX
Welcome to DataX: Empowering Your Data Management 👋
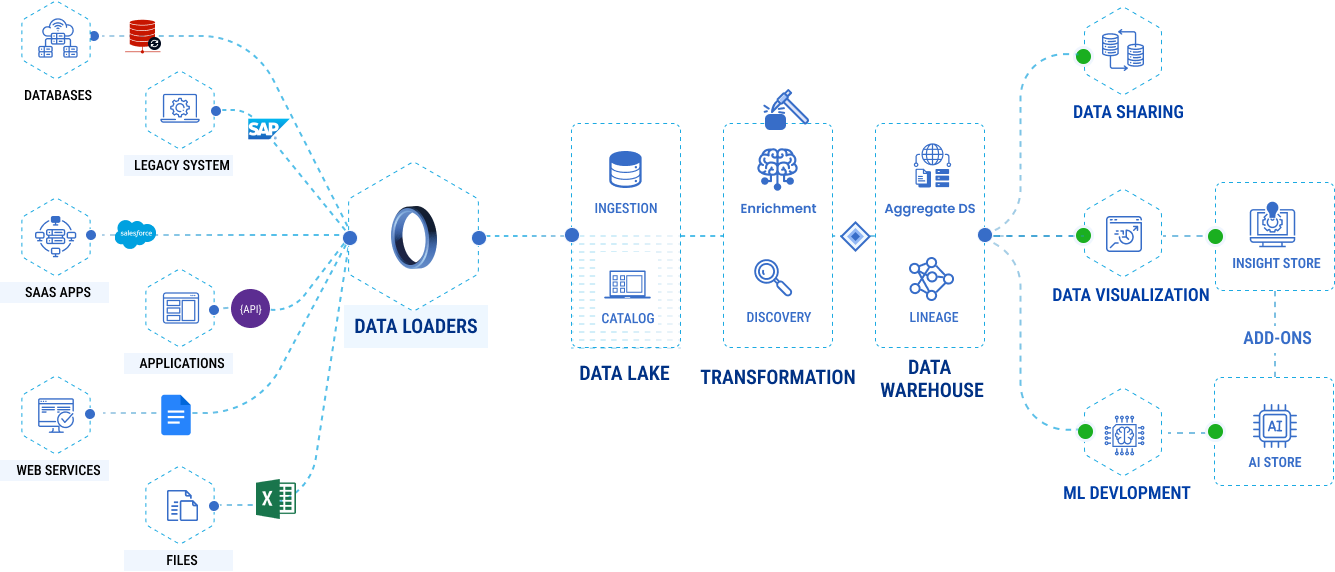
DataX is an all-encompassing SaaS solution tailored to meet your diverse data management needs. With DataX, you gain seamless access to your data, facilitating effortless connections, smooth transformations, and efficient loading into destinations. This platform not only offers data integration but also empowers users to visualize their data directly from its sources or leverage the integrated data warehouse within DataX. Whether you're connecting to data sources, performing transformations, loading data, or visualizing insights, DataX provides a user-friendly environment to streamline your complete data journey.
Unveiling DataX's Purpose 👀
DataX addresses a multitude of challenges encountered in data management. By prioritizing output over time spent on data ingestion, DataX presents a comprehensive solution to overcome inefficiencies in the process. It's widely acknowledged that data professionals invest a significant portion of their time, nearly 60%, on tasks like data ingestion and preparation, leaving only limited time for insights.
DataX effectively resolves this dilemma by offering a unified platform that encompasses all essential components for the data lifecycle. By harnessing the power of intelligent AI capabilities, DataX significantly reduces the manual effort invested in tasks. Key solutions provided by DataX include:
- Streamlined integration across diverse cloud sources.
- Elevated customer engagement and audience development.
- Automated data pipelines, eliminating manual data prep.
- Drastically reduced data preparation time.
- Equipping data-savvy individuals with robust data preparation tools.
- Simplified data import and export with major third-party services.
- Ensuring robust security measures and data protection.
With DataX, organizations can conquer these challenges and optimize their data management processes efficiently.
Exploring DataX Modules 🚀
Connector Framework (CF)
DataX's Connector Framework (CF) boasts a rich collection of over 120 connectors, spanning from Analytics platforms to Data Warehouses. Whether you're dealing with databases, cloud storage, APIs, or more, CF empowers seamless and swift integration with your data sources.
The Connector Development Kit of DataX empowers developers to rapidly create connectors, eliminating the need for manual connector development. With this innovative toolkit, DataX developers can expedite the creation of new connectors designed specifically for API-based sources. Notably, DataX's streamlined development process enables the construction of a new connector in under two weeks, showcasing DataX's commitment to efficient solutions. This feature accelerates users' ability to connect with diverse data sources and harness the power of their data more swiftly than ever before.
Sources
- Comprehensive Source Support: DataX's Connector Framework (CF) accommodates a wide array of data sources, including databases like PostgreSQL, MySQL, and MongoDB, cloud storage solutions such as Amazon S3 and Google Cloud Storage, as well as APIs like Salesforce and Shopify.
- User-Friendly Configuration: CF provides an intuitive interface for effortless configuration and setup of connections to various data sources.
- Schema Discovery: CF automatically detects and retrieves schemas from connected sources, simplifying the data integration process.
- Incremental Data Sync: CF facilitates incremental data synchronization, allowing users to efficiently update only the newly changed or added data.
Destinations
- Data Warehouses and Databases: CF supports popular data warehouse and database destinations, including BigQuery, Snowflake, Redshift, and PostgreSQL.
- Efficient Bulk Loading: CF offers efficient bulk loading capabilities to swiftly load substantial volumes of data into destinations.
- Data Consistency and Reliability: CF ensures data integrity and reliability during the integration process, incorporating built-in error handling and retry mechanisms.
- Incremental Data Loading: CF supports incremental data loading into destinations, enhancing performance and reducing data duplication.
- Cloud Storage Support: CF enables users to store intermediate data in cloud storage services like Amazon S3 or Google Cloud Storage for easy accessibility and backup.
This suite of capabilities provided by DataX's Connector Development Kit and Connector Framework simplifies the process of connecting to diverse data sources and destinations, ensuring smooth and reliable data integration.
Data Pipeline 🛢️
DataX empowers users to effortlessly construct Extract-Transform-Load (ETL) pipelines, seamlessly bringing data from various sources, performing necessary transformations, and efficiently loading it into a data warehouse or any preferred destination. This comprehensive functionality provided by DataX enables users to effortlessly manage the entire data pipeline, ensuring smooth data integration, optimal data wrangling, and efficient data storage, thereby facilitating effective data utilization and analysis.
DataX provides a wide array of transformations that can be categorized into two levels: Column Level and Node Level transformations.
Column Level Transformations:
DataX offers an extensive collection of over 70 transformations, including Format, Aggregate, Filter rows, Dates, and more. These transformations are conveniently accessible through the user interface (UI), eliminating the need for users to write any code. This intuitive approach empowers users to effortlessly build and customize transformations according to their specific data requirements, simplifying the data processing workflow.
By offering a rich set of pre-built transformations and a user-friendly UI, DataX ensures that users can efficiently manipulate and enhance their data without the complexity of manual coding, thereby facilitating a streamlined and intuitive transformation process.
Node Level Transformations:
These are the transformations available within the Pipeline, allowing users to directly apply transformations to one or more nodes, such as Join and Merge.
The following transformations are available:
- Join: Combines data from multiple sources based on a common key or condition.
- Merge Row: Consolidates rows with similar data, eliminating duplicates and organizing data effectively.
- Fuzzy Join: Matches and joins data based on approximate or fuzzy matching criteria, accommodating variations and inconsistencies in the data.
- LookUp: Retrieves additional information from a reference table based on specified conditions or keys.
- Split: Divides a single column into multiple columns based on a delimiter or specified rules.
- Merge Column: Combines multiple columns into a single column, facilitating data consolidation and organization.
- Code Editor: For users who can write code in pyspark, the Code Editor is a valuable tool, especially when UI-based transformations are not available in DataX.
Data Profiling:
DataX provides insightful data profiling on sample sets of loaded data, identifying missing rows, outliers, and more. This enhances your understanding of the data's characteristics, ensuring high-quality insights.
Data Storage 🗄️
DataX uses Blob Storages like GCS, S3 as a data lake and data warehouse rather than using expensive solutions like BigQuery and Redshift. Here are the features of DataX’s Data Storage:
ACID Transactions:
DataX provides full ACID (Atomicity, Consistency, Isolation, Durability) transaction support, ensuring data consistency and reliability. It allows for atomic commits, rollback, and isolation guarantees, making it suitable for mission-critical data processing.
Schema Evolution:
DataX allows for schema evolution, enabling users to evolve their data schemas over time without affecting existing data. This feature supports schema enforcement, schema evolution history tracking, and backward compatibility.
Time Travel:
DataX incorporates time travel capabilities, allowing users to query and access data as of specific points in time. It enables easy rollback to previous versions of data or the ability to query data at a specific historical state.
Metadata Management:
DataX includes built-in metadata management capabilities, maintaining metadata information for tables and schemas. It supports metadata consistency checks, table-level statistics, and schema evolution tracking.
Optimized Data Compaction and Z-Ordering:
DataX optimizes data storage and retrieval by implementing data compaction techniques and Z-ordering for column-based storage. This improves query performance and reduces data storage costs.
Data Versioning and Auditing:
DataX provides built-in versioning and auditing features, allowing users to track changes, understand data lineage, and perform data quality audits. This enhances data governance and compliance.
Scalability and Compatibility:
DataX is designed to handle large-scale data lakes and seamlessly integrates with popular data processing frameworks, such as Apache Spark. It supports parallel processing and can scale horizontally to accommodate growing data volumes.
Visualisation 📊
DataX Visualization is a platform that empowers users to explore and visualize data in a user-friendly and interactive manner. It provides a rich set of features, making it a versatile tool for data exploration, visualization, and reporting. With its intuitive interface and extensive functionality, DataX Visualization enables users to derive insights, make data-driven decisions, and share visualizations with ease.
Key Features of DataX Visualization:
Interactive Data Exploration:Allows users to interactively explore data by slicing, dicing, and drilling down into various dimensions. Users can filter, group, and aggregate data to uncover patterns, trends, and outliers.
Visualizations and Dashboards:Offers a wide range of visualizations, including charts, graphs, maps, and more. Users can create interactive dashboards by combining multiple visualizations, facilitating a comprehensive view of data and insights.
SQL Editor and Querying:Provides a SQL editor interface that enables users to write and execute SQL queries directly within the platform. This feature allows advanced users to perform complex data manipulations and calculations.
Ad Hoc Reporting:Allows users to create ad hoc reports by defining custom metrics, dimensions, and filters. Users can generate on-demand reports with dynamic data and export them in various formats.
Data Source Connectivity:Supports a wide range of data sources, including relational databases, cloud storage, and big data platforms. It seamlessly connects to data sources, enabling real-time or scheduled data refreshes.
Data Permissions and Security:Offers robust data permissions and security features. Users can define role-based access controls, ensuring data privacy and restricting access to sensitive information.
Collaborative Environment:Provides a collaborative environment where multiple users can work on the same project simultaneously. It supports annotations, comments, and sharing capabilities, fostering collaboration and knowledge sharing.
Integration with External Tools:Integrates seamlessly with other BI tools, data platforms, and data science libraries. It supports integration with popular tools like Apache Spark, Tableau, and Jupyter Notebooks.